Zero Trust and Zero Trust Network Access (ZTNA) are very popular topics these days. And—as you may have suspected—they are not the same. Zero Trust is a foundational architecture approach while ZTNA is specific to securing network access for a hybrid work environment.
Palo Alto Networks introduced ZTNA 2.0 earlier this year. ZTNA 2.0 overcomes the limitations of the current “1.0” approach, and provides better security outcomes to support the hybrid workforce needs of today’s digital and cloud-first businesses.
In this blog, I’m going to describe Zero Trust and ZTNA, how they relate to each other, and how Palo Alto Networks uses ZTNA 2.0. As a security company and a first customer of our own products, we leverage a Zero Trust architecture as well as ZTNA 2.0 principles not only to manage our hybrid workforce, but also to protect our “crown jewels”—our intellectual property, customer data and employee data.
Let’s Start with Zero Trust
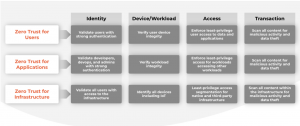
Zero Trust is defined as a methodology to secure an organization by eliminating implicit trust and continuously validating every stage of a digital interaction. Why is this important? Zero Trust allows a company to protect itself by protecting users, applications and infrastructure, as shown in figure 1 below.
- Users: This is about verifying every aspect of the user, starting with the user’s identity. Is the user who he really claims to be? What are the user’s device, the user’s role and the correct privileges for that role, and the data in the user’s transaction?
- Applications: This is about protecting key apps, data and administrative interfaces by ensuring only authorized users and legitimate service accounts have access to applications and data.
- Infrastructure: This is about ensuring that only authorized users—such as admins/super users—can access the infrastructure (e.g., routers, IoTs, servers), identify and protect the infrastructure from vulnerabilities (recall Log4j, Spring4Shell 😡). Is the infrastructure behaving normally or is something off?
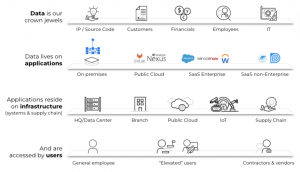
At Palo Alto Networks, we implement Zero Trust as a function of data, users, applications and infrastructure as shown in figure 2 below. Our “crown jewel” data is critical and lives on ~200+ applications across various data centers and in the cloud.
About 15,000 users—including employees, contractors, administrators, software developers and others—can access this data from anywhere in the world based on their privilege levels and job functions. Whether it’s the home, corporate locations, airports, cafes, or the beach, we need to ensure the highest security.
How Does Palo Alto Networks IT Implement ZTNA 2.0?
Palo Alto Networks has been operating in hybrid mode for the last three years and we use Prisma Access to secure our hybrid workforce. Security in a hybrid environment needs continuous trust verification along with continuous traffic inspection for all apps and all data to ensure protection from data leaks, exploit attempts and malware, as well as tracking of user behavior, including user identity and user privilege level management.
ZTNA 2.0 delivered with Prisma Access gives us exactly this capability. This is why ZTNA 2.0 is better suited for securing a hybrid workforce versus ZTNA 1.0 (see comparison).
Let me walk you through how we use ZTNA 2.0 in the context of five key lifecycle principles, which are the critical building blocks to implementation. Please refer to figure 3 as you go over these principles.
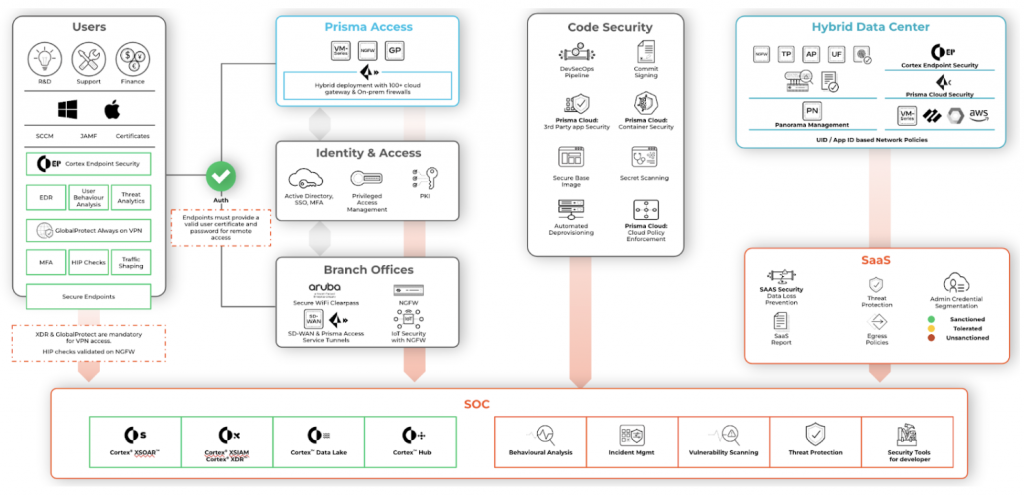
Principle #1: Least-Privilege Access
We granularly identify applications at the app and sub-app levels in our on-prem and Prisma Access security policies. Policy Optimizer (a feature of NGFW) is a great starting point, which shows application usage and risk associated with App-IDs. If an App-ID with a high risk is a business necessity, then we review this with our InfoSec team on a recurring basis.
How this is implemented:
In each case below, the parent App-IDs contain various other sub App-IDs that actually need to be blocked for security reasons. Here are some examples:
- ms-ds-smbv3 is a part of “ms-ds-smb”. The reason we do not use the parent App-ID “ms-ds-smb” is because it includes smbv1 and smbv2, which are high-risk App-IDs.
- We use snmpv3 instead of using parent App-ID “snmp”, which includes snmpv1 and snmpv2, considered less secure.
- We use boxnet-base instead of parent App-IDs “boxnet”, which includes high-risk App-ID “boxnet-uploading”. Boxnet-base also has better certifications, i.e., fedramp, soc2, truste.
Principle #2: Continuous Trust Verification
Based on the user behavior, device posture and app behavior is needed for the user, the device, and the application once access is granted.
How this is implemented:
- User-ID, user verification and user behavior: We use User-ID in almost all our security policies and derive User-ID based on Active Directory, GP Agent and wireless controller integration with our on-prem security as well as Prisma Access. AD integration allows us to define security policies based on the user’s current job function, e.g., only engineering users have access to source code repositories. If the user changes job roles, say to a non-engineering role, his access to source code will automatically be revoked without changing any security policies. We also use adaptive MFA for user verification and user behavior management to make sure the user is who he’s claiming to be, in addition to using user and machine based certificates. For admin roles, we require privileged access management for access to jump servers.
- Device verification and device changes: We enforce GP Agent with always-ON secure tunnel and enforce HIP checks before users access corporate network resources. HIP checks ensure that the user device is at an acceptable security level. For example, does the device have an endpoint security agent, such as XDR, running in real-time mode? XDR uses behavioral-threat protection, which baselines device behavior.
- Application behavior: This is tracked with a combination of XDR’s capabilities and firewall rules using sub App-IDs to track app behavior both at the endpoint and over the network. If the application deviates from baseline behavior, XDR can alert the SOC and even leverage our automation engine to take action by either restricting or completely isolating the end point from the network.
Principle #3: Continuous Security Inspection
We have to do ongoing inspection of all traffic, even for allowed connections, to prevent all known and zero-day threats.
How this is implemented:
- Cloud delivered security services: We use CDSS subscriptions across our entire Palo Alto Networks firewall platform, including Prisma Access. These services inspect all sessions for known and zero-day malware using WildFire®, suspicious sites using Advanced URL Filtering, the integrity of each DNS lookup using DNS Security, the behavior of each IoT device using IoT Security, and prevention of C2 attacks using Advanced Threat Prevention. Additionally, we use Wildfire as a service with XDR endpoint security for malware analysis, in case malware does make its way to an endpoint.
- Data logging and analysis: We send all logs, including Prisma Access and on-prem firewall traffic logs, application logs, endpoint logs, IoT device logs and compute logs, to Cortex Data Lake where they are stitched together to produce various views for monitoring security controls by our SOC, Infrastructure Security and InfoSec teams.
Principle #4: Protecting All Data
This is done using our Next-Gen CASB (Cloud Access Security Broker) and Enterprise DLP (Data Loss Prevention).
How this is implemented:
We use Enterprise DLP and SaaS Security to prevent data loss and protect SaaS applications from undesirable exposure.
- Enterprise DLP: We prevent leakage of passwords, certificates (both on-prem and in our cloud instances), PII, confidential data and customer data. DLP is integrated using consistent security policies on both our on-prem firewalls and Prisma Access.
- SaaS security: With ~60% of our applications being Saas applications, we use SaaS API Security to protect against unnecessary exposure of application data permissions and to monitor data loss. For example, with Google Drive, we monitor access permissions of any corporate data to competitor or personal email domains. To protect our customer data, we prevent any sharing of customer information (e.g., tech support files) over Google Drive or Slack and any shared data is tombstoned. We also monitor bulk downloads from SaaS apps when the patterns stand out of the ordinary.
Principle #5: Securing All Apps
We safeguard all applications used across the enterprise, including modern cloud-native apps, legacy private apps and SaaS apps. This includes apps that use dynamic ports and apps that leverage server-initiated connections.
How this is implemented:
Here’s how we secure applications supporting business functions:
- Securing VoIP phones: We have several policies allowing VoIP applications and supporting services between corporate users, VoIP based infrastructure, cloud-based VoIP and call center services. We can be very specific to the application port level, such as only allowing SIP and necessary protocols for VoIP and video services.
- Securing server-initiated apps: In order to support server-based applications in our cloud and data centers, we have a standardized secure VPC design with VM-series firewalls, which inspect all traffic with advanced L7 protection. We connect Prisma Access to both cloud and data center VPCs and have server address-group based security policies for allowing server apps to consume cloud based services, e.g., SaaS services or app patches. These security policies are tightly tuned to the service, app and URL level, and require certificate/mTLS based authentication.
- Securing IT support connecting to user’s machines for remote troubleshooting: This can be tricky because allowing remote connections to a user machine is generally a bad practice. However, temporary policies can be defined to only allow specific users (based on User-ID) form specific bastion-hosts to other specific users who are having issues. This keeps the policies as tight as possible.
Our North Star
ZTNA 2.0 lifecycle principles require ongoing activities in which IT Network Security teams, DevSecOps teams, InfoSec teams and SOC teams review and tighten:
- Application risk and security policies based on actual application usage
- Mechanisms to track and improve risk management of user and device behaviors by improving IAM and endpoint security
- Improve coverage of inspection for all transactions such as malware, C2, malicious URLs/DNS lookups, IoT behavior, data leaks and SaaS application security posture and data sharing permissions
We’ll be extending our coverage of ZTNA 2.0 by adopting SSPM to protect our SaaS application configurations. This will minimize the posture risk to our ever growing list of SaaS applications and harden the product capability for our customers.
A complete Zero Trust architecture is our North Star. ZTNA 2.0 is an evolution of Zero Trust for network access to address security in a hybrid environment focused on the user, device and application behaviors with enough granularity to protect every transaction.
I hope this has been useful to you in gaining practical insights into ZTNA 2.0. Getting started with the five key lifecycle principles of ZTNA 2.0 and coming up with an action plan is key to implementing ZTNA 2.0. To learn more, check out these resources:
https://start.paloaltonetworks.com/the-evolution-of-ZTNA
https://start.paloaltonetworks.com/zk-research-ztna20-is-imperative-now.html
https://start.paloaltonetworks.com/ztna-for-dummies.html



