At Palo Alto Networks IT, we build customer facing applications running on GKE. For example, supporting 60,000+ global customers or providing Licensing & Content updates for 1.5+ million next-generation firewalls.
In Kubernetes, it’s important to enforce the traffic security within the cluster and have visibility of the east-west traffic flows. Prisma Cloud Identity-Based Microsegmentation (a.k.a. Aporeto) is a good way to isolate and provide logs for the traffic between cloud native applications.
We’re deploying it to secure these applications in a way where we can provide security at a velocity that doesn’t slow down our developers. How do we do it? Developers are the closest group of people who understand the required traffic flows of the services. They are also used to file pull requests regularly to the source repositories. We will show you the pull request way for managing our Microsegmentation policies!
The Limitations
Our primary use case is to have Microsegmentation secure our east-west traffic within a GKE cluster as depicted in the figure below with an orange arrow:
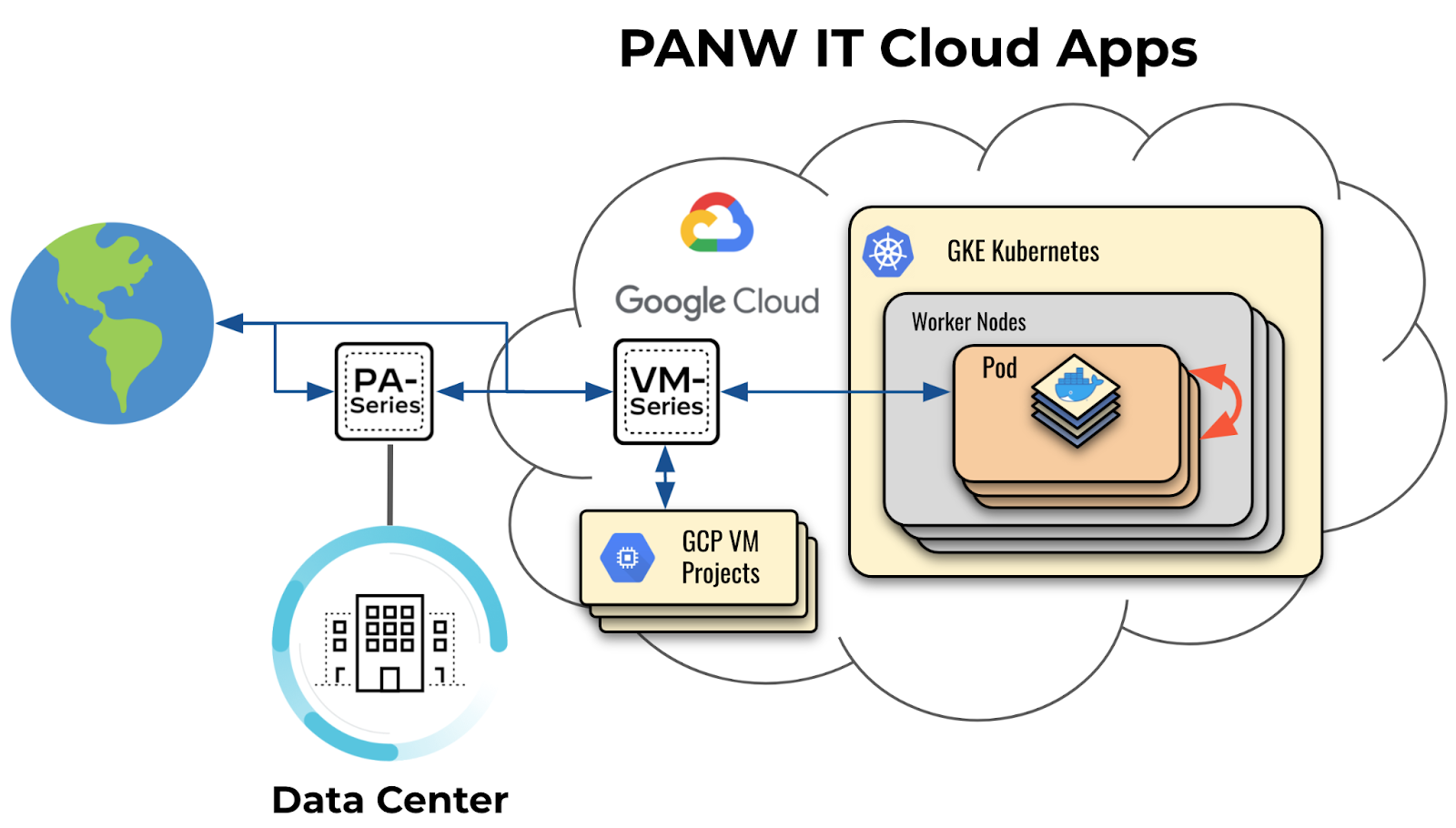
Kubernetes Network Policies is one of the alternatives to Microsegmentation. However, there are a number of limitations along with the ones listed officially. Two limitations stand out:
- The flow traffic and security events (e.g., blocked/accepted traffic) are not logged when using Network Policies solely. GKE might have a feature for this in the VPC flow logs though.
- Everything in the network policies is around an IP/CIDR and a pod/namespace label. There’s no DNS-based FQDN in the policies described here.
On the other hand, Microsegmentation is very flexible in the policy definition. First it’s based on identities or tags coming from the deployment context or the users. Also, the policy can be in any Microsegmentation namespace level, allow/reject in different protocols and ports. The policies are also hierarchical between the parent and child namespaces. Microsegmentation also logs all the traffic flows and DNS requests.
With Great Flexibility Comes Great Responsibility
After several months of using the product, we think we got it working pretty well based on two aspects:
- Assumption
- We are based on zero trust to deny everything, and allow flows explicitly. Hence, we are focusing only on the “allow” traffic.
- Pods can talk to other pods freely within the same Kubernetes namespace. That means we are using k8s namespaces to segment our workloads.
- There will not be a single administrator to control all the policies. Developers, SREs, and InfoSec will be part of the process.
- Tools
- An Aporeto k8s operator (CRD) was implemented to sync the policies using kubectl and yamls to avoid configuring the other CLI tool from the product: apoctl.
- A CICD pipeline to apply the policies from source repository to Microsegmentation server (GitHub + Drone CI + Harness CD).
- IT developed a Microsegmentation Policy Generator service to recommend the policies of our 200+ namespaces based on the current traffic.
Now, to operationalize this, we designed a flow as follows:
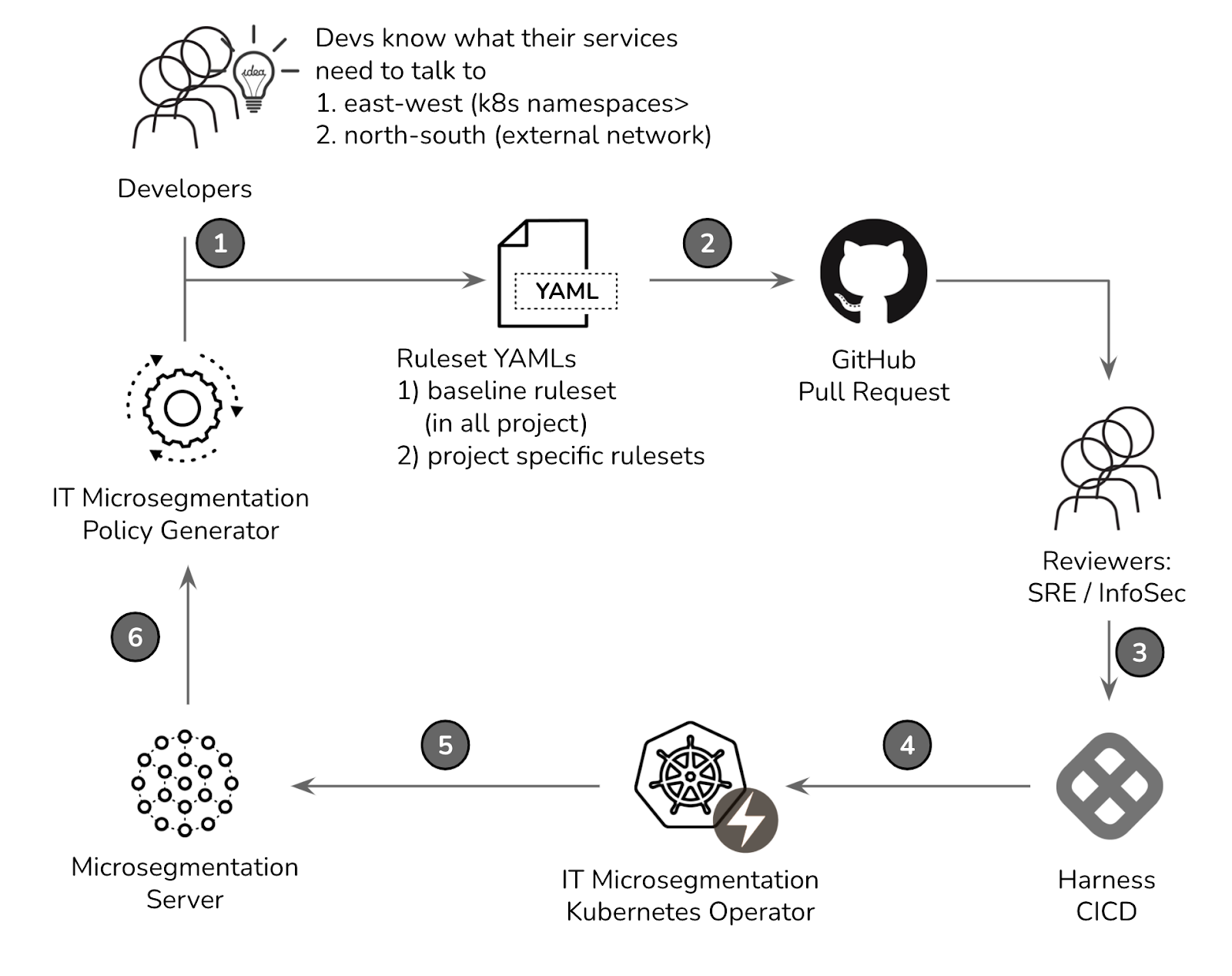
- Developers can utilize a “policy generator service” to get a basic set of policies derived from parsing the flow logs from the Microsegmentation server. They also have some ideas of what their services need to communicate with. Then they will modify the policy YAMLs in a source tree.
- Pull request (PR) will be created on GitHub to pull in different reviewers from SRE and InfoSec teams.
- Reviewers will approve/disapprove the PR accordingly, and a PR may be merged to the main branch.
- Our CICD pipeline consisting of Drone/Harness will deliver the policy changes to the GKE with our Microsegmentation k8s operator.
- The operator will fire APIs to update the policies on the Microsegmentation server.
- The traffic flow logs will be monitored 24/7. New recommendations will be available if a new flow is detected.
Please check out the video for a live demo of the flow shown in Figure 2.
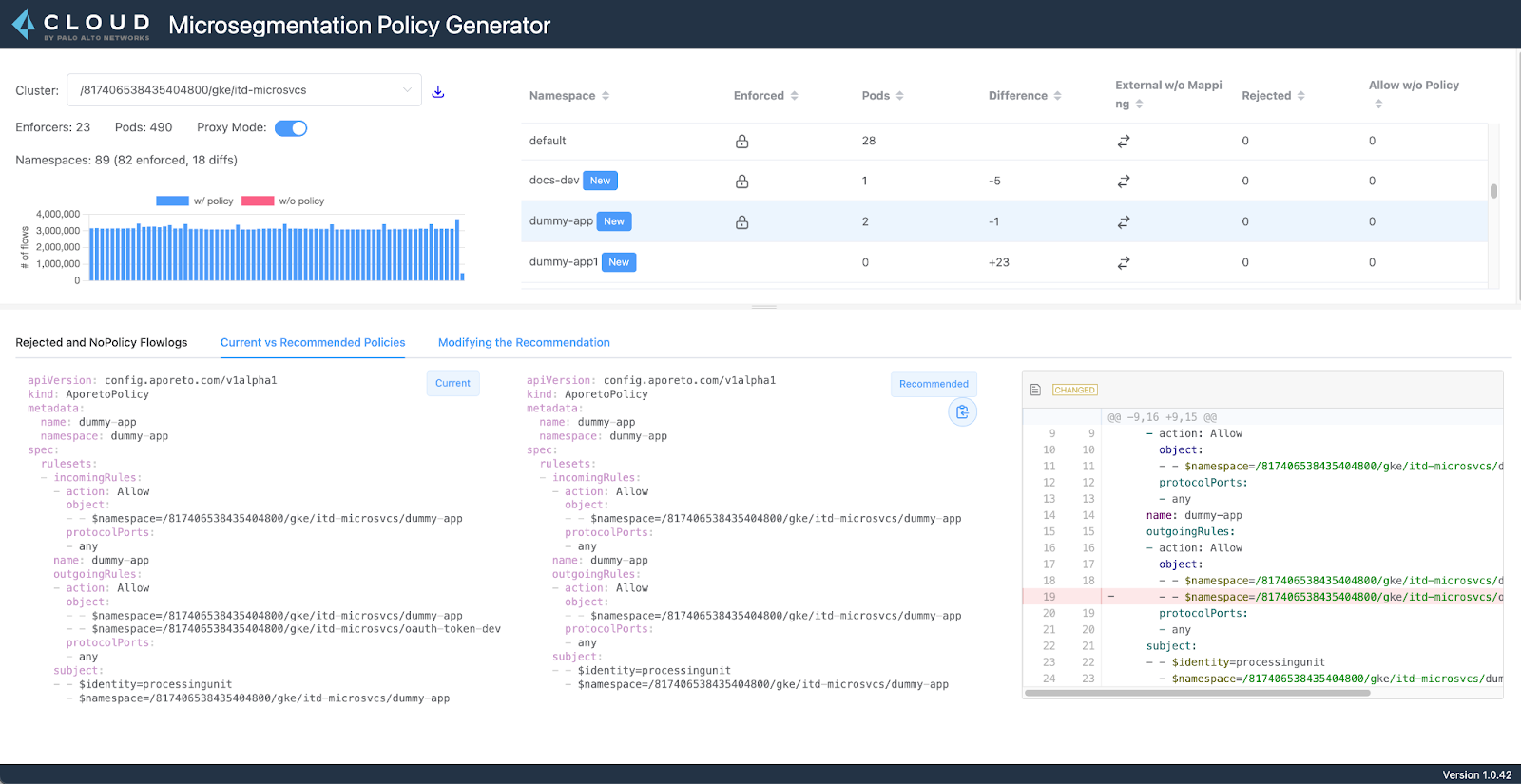
In an earlier post published on Tech Insider, the “Aporeto policy generator” I showed was actually version 1. This version 2 was a complete rewrite with a web application running off your laptops. One of our First Customer team’s charter is to disrupt! We do it with new products and we bring them from design to production. This policy generator is one of the examples where we designed the UI and got rapid prototype feedback from customers (IT developers in this case). In figure 3, the UI is showing developers the new recommendation changes in each namespace clearly.
While the policies recommendation is obviously the main focus of this application, it also provides more information about the blocked flows, allowed flows without policies, and also the general metrics of the deployment.
Developers Win
In short, we turned the problem of an area that’s mostly ignored or delayed by the infrastructure and security teams to having developers participate in this security process early on for speed.
As of today, we’re enforcing policies for a vast majority of the Kubernetes namespaces. We’re letting the developers use the self-service to cover the remaining namespaces to operationalize the process.
Writing the code for the policy generator, Kubernetes operator, and the CICD pipeline took about 3 months. However, we still need more time to educate our developers, SRE and InfoSec teams on this new process and let them get used to it.
Identity-based Microsegmentation from Prisma Cloud is awesome. Just take a look at this go binding API repository and you will be amazed at how structured their work is. I’m sure you are already excited to check it out for cloud native applications to intercommunicate in reliable pathways.



