To secure your enterprise infrastructure, your firewalls have to be up-to-date to stop all malicious attempts. It takes just one good shot from a hacker to cause untold damages.
At Palo Alto Networks we keep our firewalls updated constantly. But you already know that. What you may not know is that the most significant challenge has been about speed. Namely, how fast can we release new updates to our firewalls in a reliable and efficient way for users?
As of this writing, Palo Alto Networks support 1.5 million next-generation firewalls. These millions of firewalls have to continuously update their software against continuous new threats.
This is no easy task. So in 2017 we started a journey to modernize our infrastructure by migrating to the public cloud, which provides a rich set of easy-to-consume services that are far more scalable, reliable, and cause less operational burden for customers.
Interesting challenges came up, including for R&D and IT to build and serve new signatures in almost real-time (5 minutes!). This, by the way, is unique in the cybersecurity industry. On top of that, additional verification needs to be conducted to make sure that these updates protect against the latest threats and are consistent with other features of the firewalls.
Dynamic content update service was a perfect candidate to leverage Google Cloud Platform (GCP) to support our increasing workload of firewalls.
Traditional Way to Manage Infrastructure
Before I get into how we modernized our infrastructure, it’s helpful to have a comparison point. When services were hosted in an on-prem data center, the compute environment was hundreds of VMs running across a large set of clusters on-premise load balancers with no global load balancing capability. On top of that, there were problems like:
- Administration of VMs was a nightmare
- Security and patch management was difficult
- Limited granularity in logs
- Scalability: Each month, we needed to build more machines and it became harder with each passing quarter as the scale continuously expanded
How we used to do things was not working. We needed a new approach, which boils down to: Large Problem + Curiosity + Excitement to Contribute = Solution.
In our goals of migrating to the cloud, we kept our focus on simplicity and full automation. Specifically, we wanted to:
- Convert application from monolith to microservices by peeling off various functions and launching them as independent services on the latest technology stack
- Design solution to Auto Scale
- Ensure that the solution has almost zero administration
- Establish multi-region availability of services to provide better latency to customer’s devices across the world
- Have fully automated code rollout and scalability
- Mine valuable analytics from detailed logs
We preferred to do all of this with a smaller infra footprint. Our motto is: Smaller, Faster, Better.
Technology Stack
We evaluated many different options for our technology stack, like MongoDB, ingress controller and service mesh istio, automation Chef vs. Ansible, etc., and found the following combination best at helping us achieve more reliability and ease of management:
- GKE => deployed in 2 GCP regions, the U.S. and Europe, to provide lower latency to customer’s devices based on location. We picked this since GCP knows how to run GKE best. We were not keen on spending effort in managing the platform but preferred to develop the solution on an existing platform.
- Redis => cache as much data as possible to limit DB lookups. Lower latency transaction in Memory database deployed in multi regions with bi-direction replications (one of the keys has more than 1.4M entries).
- Nginx (Why not Istio ? ) => front-end will route the traffic based on the type of API calls from customer devices. Istio ran into a scalability issue and we want to make it simple. The need is a highly scalable ingress controller with advanced routing capability and Nginx plus passed all test cases and benchmarks.
- Terraform => build the infrastructure: No brainer.
- Ansible => maintains infrastructure config and patching: Keep it simple.
- Harness + Drone => CODE rollout. We used CircleCi for a while but without an integrated CD solution, we had to struggle through custom scripts. We finally decided to move to Harness_Drone combination.
- Akamai CDN => content will be delivered to the customer’s firewall from the closest Akamai edge node. We were an existing Akamai Customer.
What Services Did We Build?
Message of the day: Provide a message to customer firewall
Content publishing : Publish a new content
Entitlement check: Check against incoming devices request
Content distribution: Signed URL shorter-lived URL can be used to download content by firewall.
Device activation: Activate new devices and services
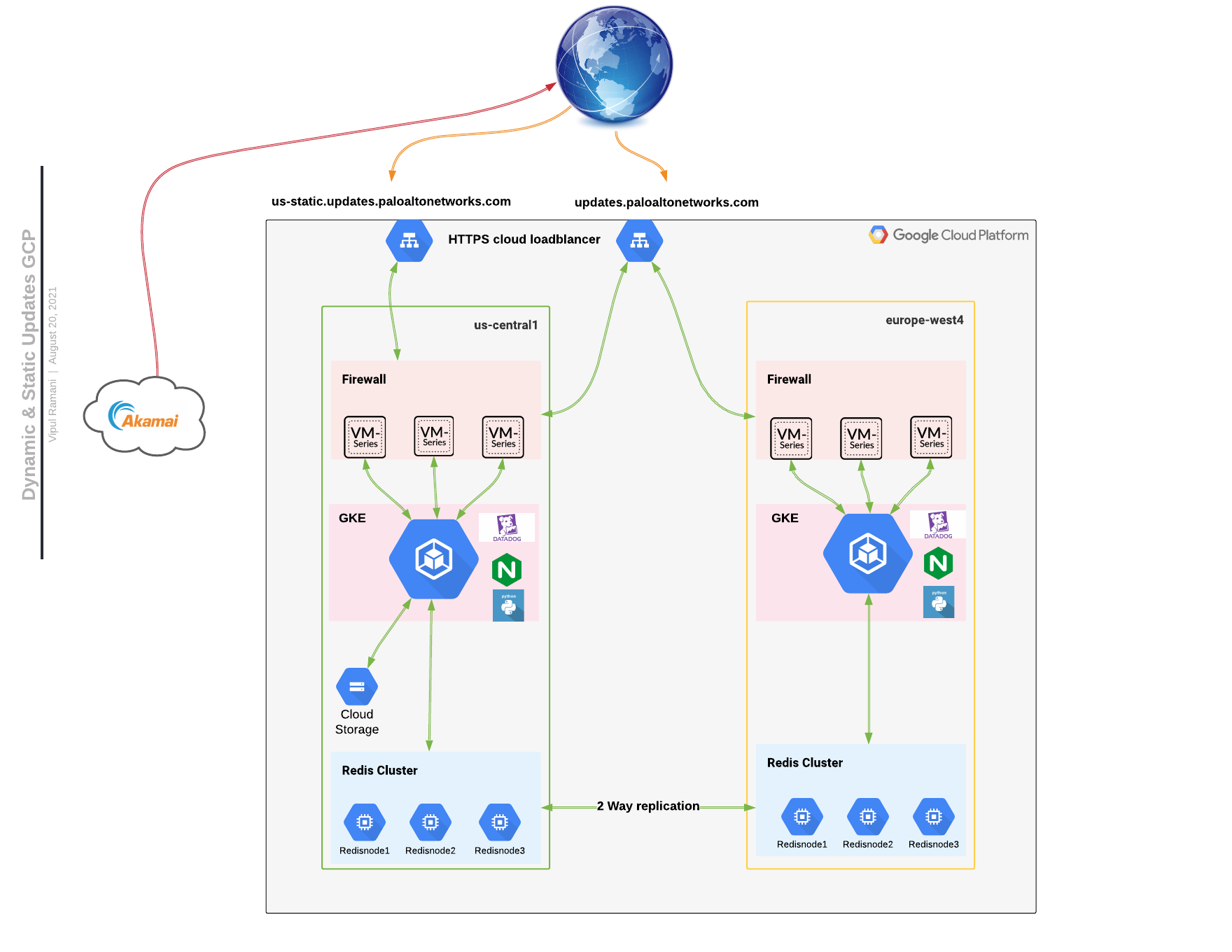
A Useful Blueprint
In addition to the architecture diagram and the technology stack, I want to share some interesting facts and stats. This may help you to design your first high-traffic microservices if you want to build highly reliable and scalable applications.
- Multi region availability of services
- 500 applications pods
- 30 GKE nodes
- 3 Nginx Plus ingress controller per region
- 3 node Enterprise redis cluster per region with bi-direction replication enabled
- 1.2T text of logs every day
- 293 M requests per day
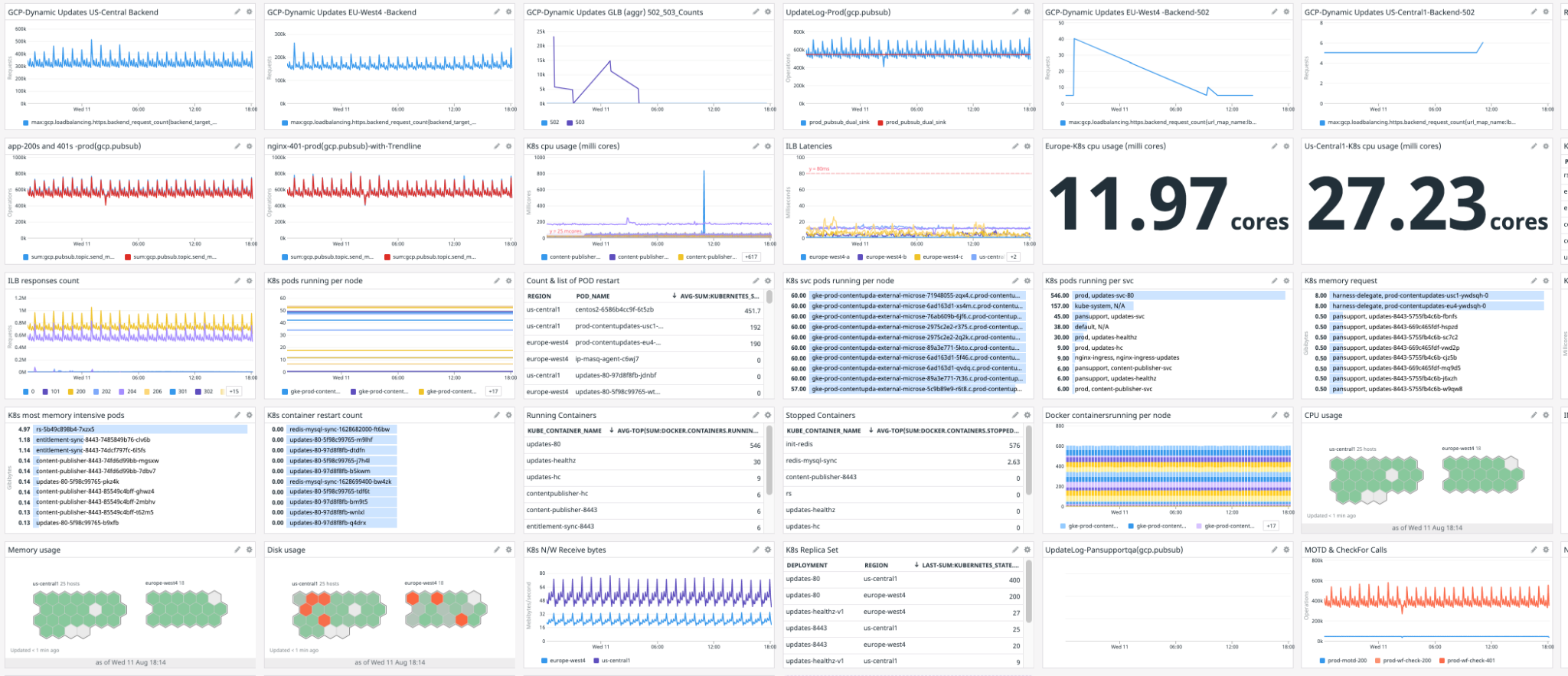
Observability
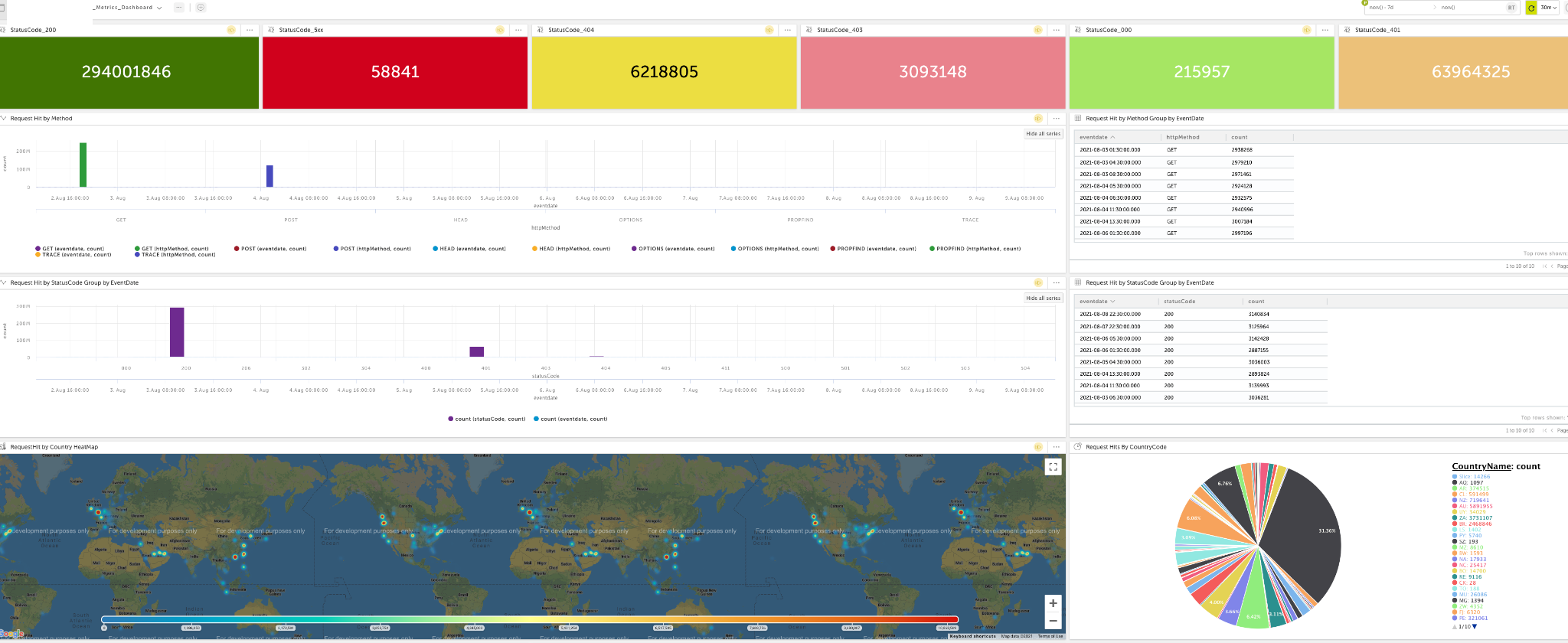
We started using application logs for further analysis, and we got a lot of interesting details. For example, we can see:
- Location of incoming requests
- Customer’s firewall version
- Latest software version downloaded by customer’s devices
- How many requests were sent by a particular firewall and how many had success or failure based on http code
For operation and product teams who are interested, here is a sample of the metrics we started collecting and measuring.
Things to Consider
When we’re designing infrastructure, there are so many things to take into account, such as keepalive-timeout value between the hop, or time taken to negotiate mTLS connections. Keepalive-timeout is one of the key factors that can improve performance and reduce error rates. We tuned the keepalive-timeout at the global load balancer, Nginx, and pod level.
This was a pretty exciting journey for me personally and for the team. Some key learnings include:
- Try to keep things simple.
- Automation is your friend, consistently producing the same result with predictability, and scale doesn’t matter; it’s truly amazing 🙂
- mTLS connection has overhead, and you have to make sure compute has sufficient amount of CPU available, because there will be at least 30% performance hit expected.
- Log mining is essential because it provides incoming requests, trends of error rates … so much information can be extracted.
And I just want to call out: No more manual tasks!



