Balancing speed against perfection is never easy, especially in high-growth companies where the ability to pivot and deliver digital capabilities quickly are valued above all else, even if it means accumulating some technical debt along the way.
All tech companies have their own struggles in this. But the way in which we have organized Information Technology (IT) at Palo Alto Networks differs from most companies and puts us in a better position.
We have a product-centric approach to IT, meaning that most work is defined into existing/new products that we manage/build. We have agile teams of engineers/scrum masters/product managers that are responsible for these products. We map our IT portfolio of projects against these product teams so that they can work on a backlog of user stories across projects as needed. This approach enables a long-term focus on product development rather than a transitory checklist of IT projects.
Organizationally, we hire full stack engineers for custom development and skilled engineers for SaaS development who functionally report into engineering leaders. The engineering leaders are responsible for the overall quality of the underlying product, including coding standards, technical debt identification and reduction, scaling, securing, automating, and making the environment highly performant working with site reliability engineers and security teams.
This organizational structure drives accountability and instills discipline into the engineering process to tackle problems in a systematic way. It also eases the challenge of addressing technical debt while maintaining business velocity.
‘Good Enough’ Wasn’t Enough
Our Customer Service Portal is an example. Designed to handle support cases and manage devices and subscriptions, it was the pinnacle of engineering 7 years ago. Over time, new features were continually developed, emergency patches were applied, business models changed, our hosting model moved from on premise to the cloud, and new platforms were integrated. Despite all this the application served the company’s needs but not without bumps. The final straw that pushed us to the brink were:
- Unexplainable outages
- Customers had to wait 13 seconds any time they wanted to create a new user
These issues led to several customer escalations. What was once “good enough” was eroding customer confidence. The situation was no longer acceptable. From an engineering perspective, no one thing was responsible for this technical debt to accrue. No one simple act would get us healthy either.
A Plan of Attack
To put our Customer Support Portal back on the right track, it was time to pay our technical debt. The first problem we tackled was how our .Net MVC monolith managed users. Our priorities included:
- We refactored several sections of code into common libraries, eliminating code smell as well as applying a consistent coding standard to improve readability. This also has the added benefit of reducing security debt (EX: Security misconfiguration, XSS and insufficient monitoring and logging to name a few) due to inconsistency.
- We measured our success via cyclomatic complexity per method/unit test coverage %, and performed red team operations to validate our security posture. We leveraged quite a few tools in this space, including SonarQube, CheckMarx, Blackduck, Prisma Cloud Compute Edition (we wanted best of breed).
The second problem was the unexplainable outages. As we touched code at every sprint, we asked ourselves how we instrument observability from the beginning. This means we needed a maniacal focus not on just if it worked, but how we’d see success at a glance to identify issues. Is our client front end overloading our notification service? During an outage we’d need a myriad of experts on a call with specific knowledge to answer this. Now we can look at a few tiles in our service map (see below) and also see synthetic test health. This combination of infrastructure health/application health and synthetic business transactions with thresholds help give us the full picture.
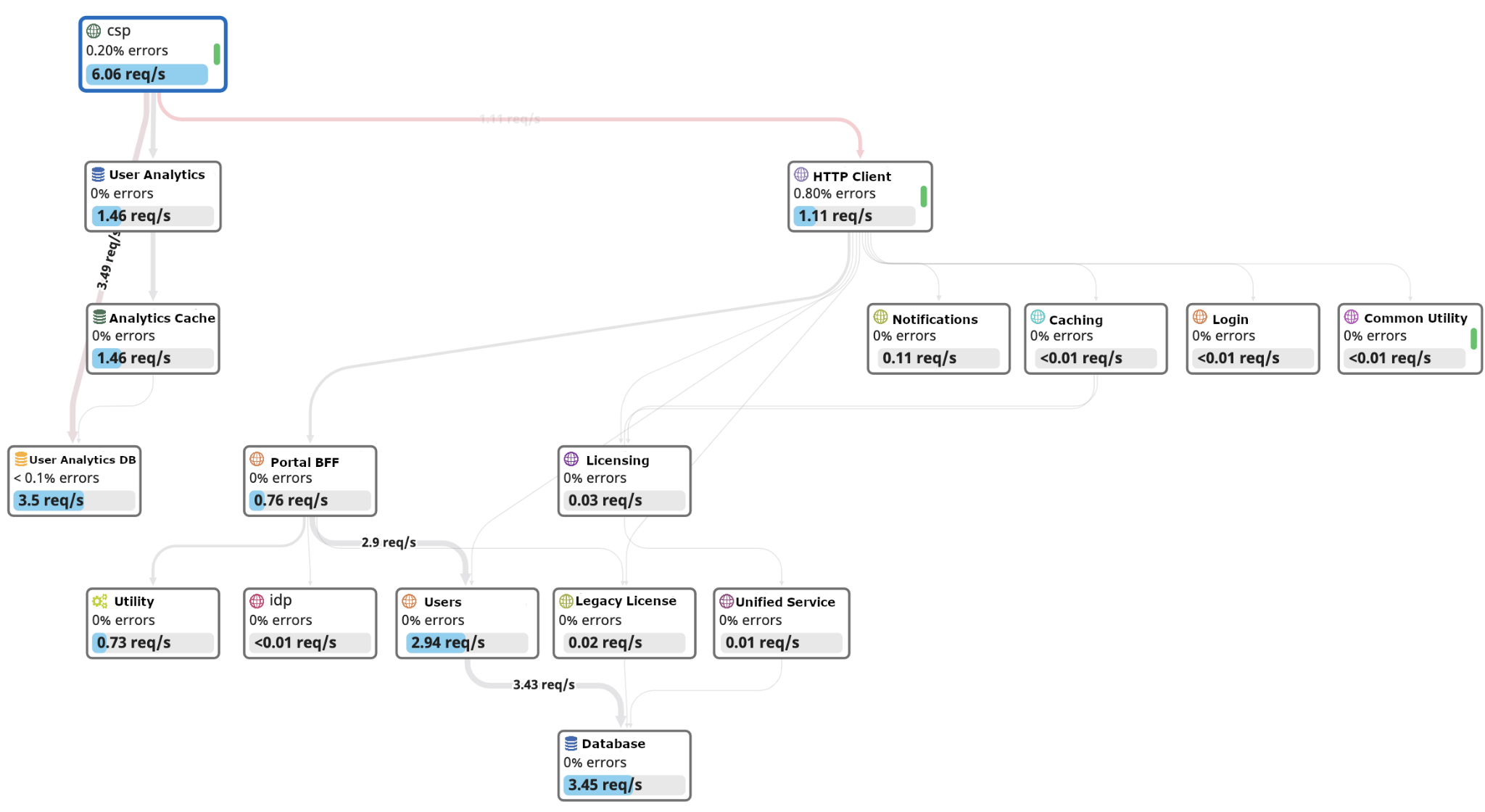
Solving these two major problems yielded huge quality improvements. Customers didn’t have to wait 13 seconds anymore to create users! Now it only takes 1 second to create a user. Our MTTR also significantly improved and L2 was able to identify and resolve a wider array of issues without engaging engineering. Our product-centric approach allowed us to be agile in our planning process so that we can reduce technical debt with every sprint. We also made sure that technical debt was a priority in each planning cycle.
Models on Managing Technical Debt
In order to avert a crisis, or worse — a disaster — engineering leaders need to engage with product managers and raise concerns in a business context so that impact can be clear. Normally, technical debt floats in the pile of development demand with no particular structure and that is assuming the team even knows to file it. More often than not it isn’t even identified, just vague hunches by senior staff on what should be done. There are two common approaches to solving technical debt: massaging capacity and tinkering with priority.
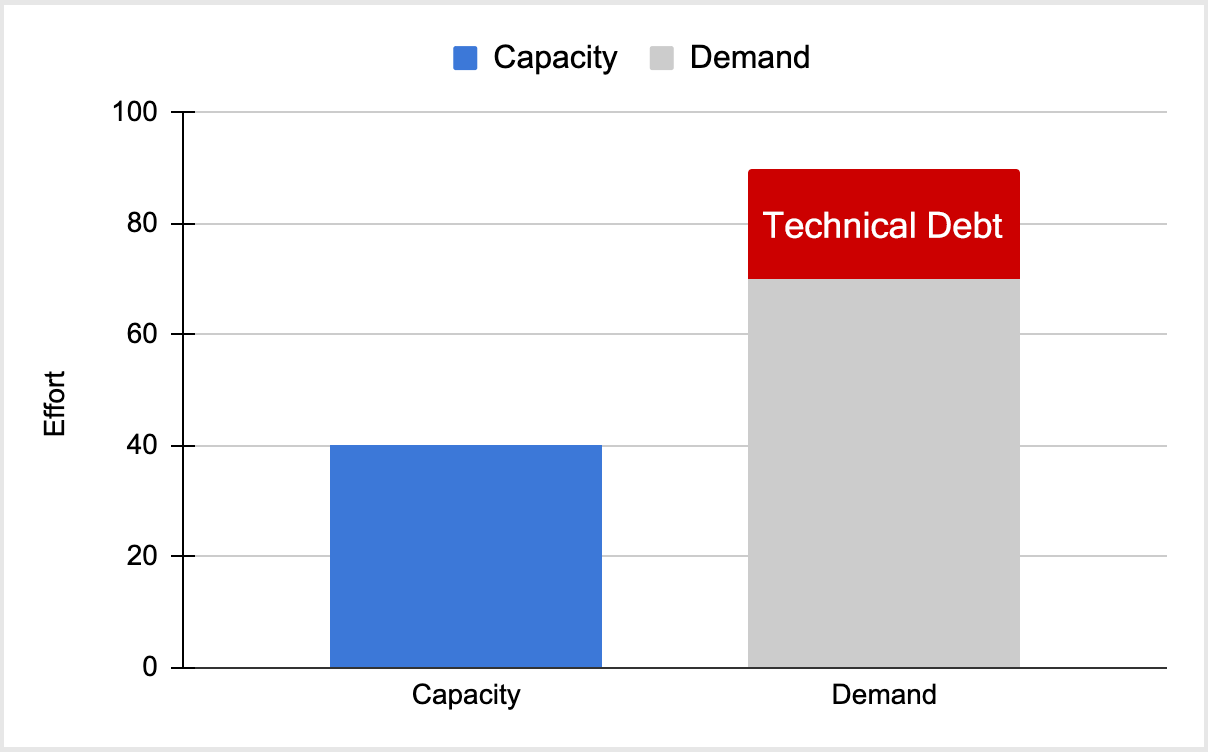
Approach 1: Capacity
Let’s bring on an army of engineers/contractors and slay the backlog as well as the technical debt. While many great books have been written about this, it seldom ends well. Technical debt often is a slog when neglected for too long, slowing ramp time for new devs and the ever present demand for new features often saps energy behind these endeavors. Assuming by some miracle it was successful, without the proper mindset in place, the environment merely atrophies after several years.
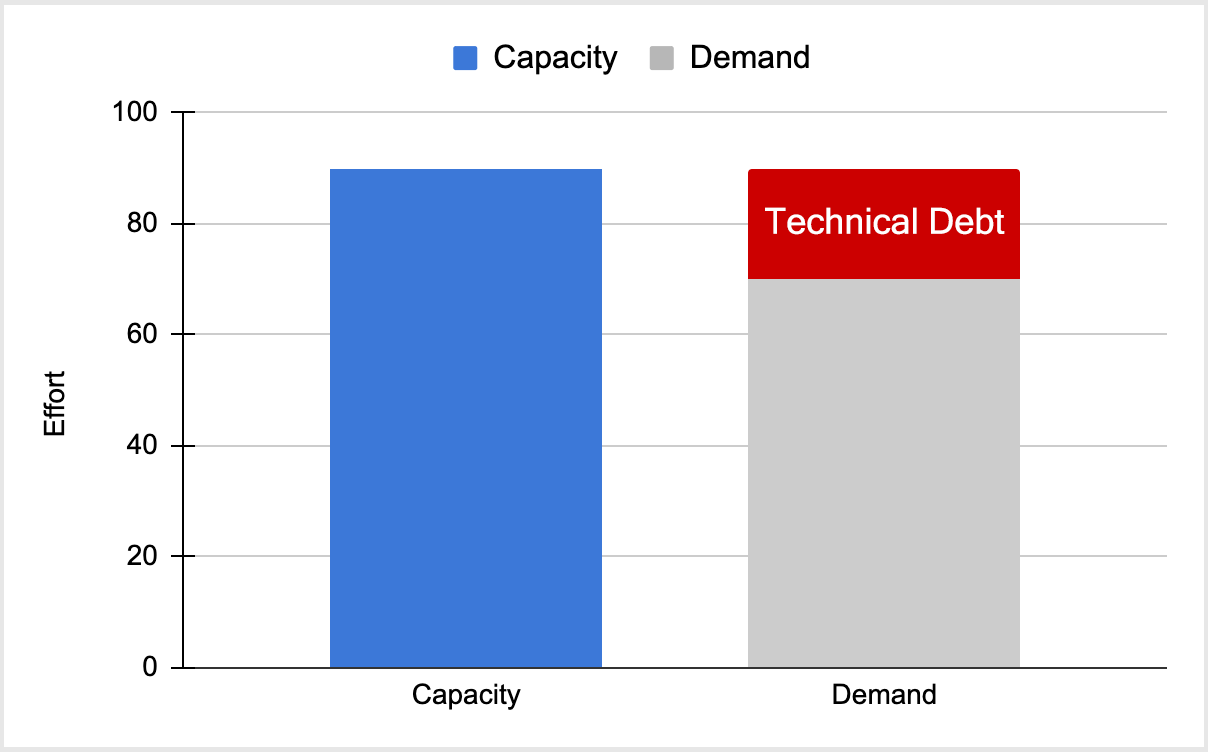
Approach 2: Prioritize
This is the most realistic and go-to way for leaders and engineers, but it’s invoked due to a crisis. Whether it’s a compromised application to pay security debt or customers unhappy with order processing taking too long, the approach to reduction is the same. The next hurdle is engineering as their knee jerk response is to rip the application apart and not devise a plan to incrementally walk their way into paying down debt. Regardless, the outcome often isn’t durable and as time goes on focus erodes.
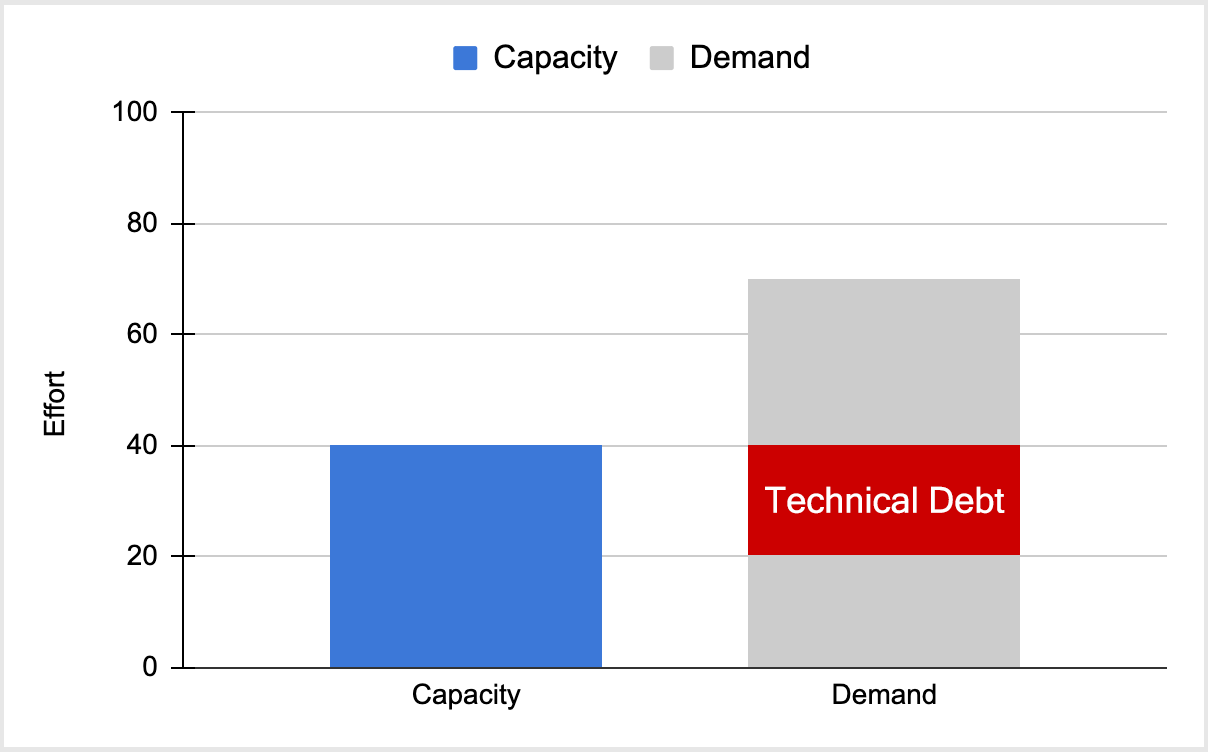
It’s Like Paying Your Taxes
The truth is you will always have some technical debt. While the approaches discussed above do help, they are typically reactive to a crisis at hand. To minimize your technical debt, it’s best to think of it like a “tax” that you continually must pay. Ask for a new feature, you pay a technical debt tax. Fixing a bug, you pay a technical debt tax. This mindset combined with a product-centric organization that’s driven by customer-centric KPIs help ensure that your engineering investment will optimize your technical stack.
In our case reducing technical debt on the Customer Service Portal dramatically improved our customer experience and raised the bar to meet our TSIA certification requirements. And the result: customer satisfaction and award!




