From an early age I was fascinated by how technology works. I was born in a small town in Ethiopia where there is limited access to technology but moved to a bigger city called Jimma when I was school age. That’s where I first saw color TVs.
As a kid, I used to ask my parents how radio and TV work, how someone’s image travels through the air and gets into a TV screen, and I used to get funny answers from my parents, who don’t have a technology background. My mother was an elementary school teacher; my father worked in city administration. My curiosity led me to study electrical and computer engineering at Addis Ababa University in the Ethiopian capital, which introduced me to the basics of coding in Java and C++.

From that time on, my interest in computers, software and hardware grew, and I started to take additional courses like networking and CGI scripting. At Addis Ababa University, one of my final projects was to develop a new image-compression application that can achieve a compression ratio of 100:1 without losing image quality. I was able to show that a higher image compression ratio can be attained compared to well-established image compression technologies like JPEG. This was one of the projects I am most proud of and it furthered my desire to pursue computer science.
After I finished university, I decided to come to the U.S. to study for a Master’s in Computer Science and was accepted into Maharishi University of Management in Iowa. At Maharishi, you are allowed to combine work and study, so I started to look for a job in the software industry. That led me to Silicon Valley.
I began my professional career as an application integration engineer, which introduced me to middleware softwares such as Mulesoft, Tibco, Oracle SOA and others as integration components. After spending 10 years on various projects at different companies a friend referred me to Palo Alto Networks’ Business Intelligence team, which was starting the journey of Big Data space. That was the main reason why I joined Palo Alto Networks in 2017 — to be part of a team that was building Big Data infrastructure from the ground up. I was very excited to work on the huge scale of information. And the distributed computing nature of the data processing? It was as interesting as can be.
Once I came to Palo Alto Networks, one of the decisions we took as part of this initiative was to build streaming applications to ingest data into a data lake for near-real-time reporting. This presented a challenge — and an opportunity — for me to learn new ways to move data from applications to data lake.
Swimming in the Data Lake
I jumped in with both feet. I took courses to learn how to build out scalable and generic streaming applications (they’re still used in our production system today). I knew what this project was going to take: long nights, a lot of reading documentation, trial-and-error and a lot of testing and fixing problems quickly. But it was worth it. I learned so much, and changed my career path from application integration to Big Data space.
As Salesforce was a main application used for reporting, one of the bigger challenges I faced was to build the first real-time data-ingestion pipeline from Salesforce into a newly constructed data lake, Hadoop (later replaced by GCP BigQuery). A key task was to build the generic producer and consumer. The issue with generic applications is how to handle changes, table addition, field addition, field removal, etc., and build a single code base to support different kinds of objects. To handle this we have to use a data format that would support such changes. We decided on Avro, so in the end, the pipelines were built out using a combination of Avro, Kafka (as the streaming platform) and a custom scheduler.
I am very happy with how this product turned out. Today the ingestion framework is able to bring close to 300 objects from Salesforce into the data lake without any code change. If a new Salesforce object is requested by a business or team, it takes only a few minutes to add to the pipeline. Similar implementations have been done for other systems like SAP, CSP and more.
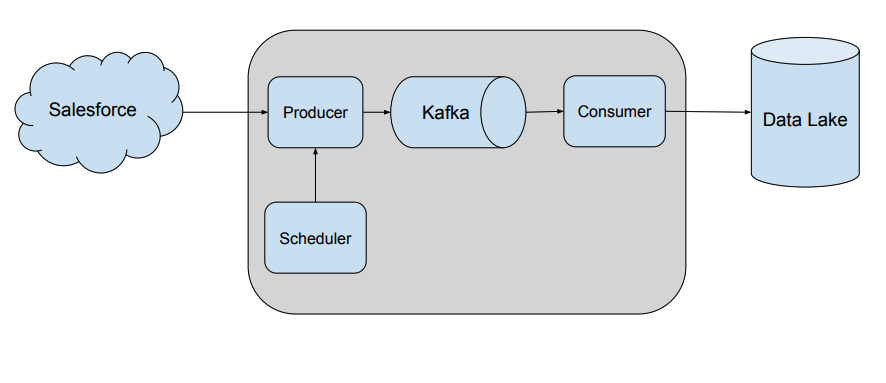
Soon, I began to lead a team of engineers that was building and maintaining the ingestion framework while ensuring data accuracy and consistency between source systems. In this role I am able to deliver various business-critical applications such as HR headcount dashboards and work on new initiatives like Data Quality Framework and others. Today I have to wear different hats throughout the day: manager, architect, code developer, code reviewer. This gives me the chance to see a product go through all the stages from drawing board to operation: design, functional requirements, business and technical challenges and finally, the implementation itself.
Embrace Your Challenges
I see challenges as opportunities. At times something can seem difficult, even downright impossible, but it is important to persevere — of course, it helps to be surrounded by such supportive colleagues as I am. Still, I believe no problem is unsolvable as long as there is a genuine desire to learn from it.
That can include your career itself. It may not follow a straight path — it can take twists and turns, like mine did. Embrace that, and try a new line of work if the opportunity presents itself. For me it was being a manager. I never thought I’d be one, but it became an opportunity. I gave it a try, and I learned and grew from it.
To come from a small town in Ethiopia, wondering how those pixelated RGB images got into TVs, to living in Silicon Valley, where I find myself working with one of the world’s leading cybersecurity companies — that’s something I never could have imagined. It is humbling and fulfilling, all at once.

If you enjoyed this post and would like to explore opportunities at Palo Alto Networks, check out our open roles. You can also read more stories like this or learn about our technologies.



