When I was in college, I attended a seminar hosted by Wen Gao, who is a Fellow of IEEE and ACM, the two most prestigious institutes of computer science in the world. He gave an excellent talk about his machine learning research. It was my first time hearing about computers being able to do far more than I expected, such as see, speak, and communicate with humans. I was shocked and decided this is my future.
I went on to get a master’s degree in financial engineering and a PhD in machine learning. After that, I worked in a research lab focusing on machine learning for computer vision and information retrieval. Then I got a faculty job in academia. During those years, I published quite a number of research papers which you can read on Google Scholar. For example, I helped build a machine learning model to recognize if there is an object of interest, e.g., dog or cat, in an image. It’s pretty similar to Google Brain, but we were doing this far earlier. 😉
A Big Move
In 2011, I made a big decision to change my career from academia to industry because I wanted to see my work applied to solving real-world problems, such as recommendation engine for e-commerce, propensity scoring for product upsell/cross-sell, traffic predictions for network operation optimization, etc.
I first heard about the term “data science” in 2012 from the Harvard Business Review where data scientist was declared as “The Sexiest Job of the 21st Century.” I mean, sure. Ok, it’s a bit cringeworthy but it caught my attention!
Today I consider myself a data scientist specializing in machine learning. (In case you’re confused by all the terms, machine learning refers to a group of techniques used by data scientists to train computers to learn from data.) But I can readily call myself a full-stack data scientist… Yes, too many terms these days.
So What Is Data Science?
If you ask data scientists who are former academics, many will tell you that data science is just science. Scientific research always involves analyzing data to arrive at conclusions.
In my view, it’s more than that. Data science is evolving very fast and has a wide range of applicable possibilities, and so to limit it to a basic definition feels elementary. An extension of that definition would be data science is a complex combination of skills such as programming, data visualization, command-line tools, databases, statistics, machine learning, and more, in order to obtain insights from data to set a course of action. The Venn diagram captures this well.
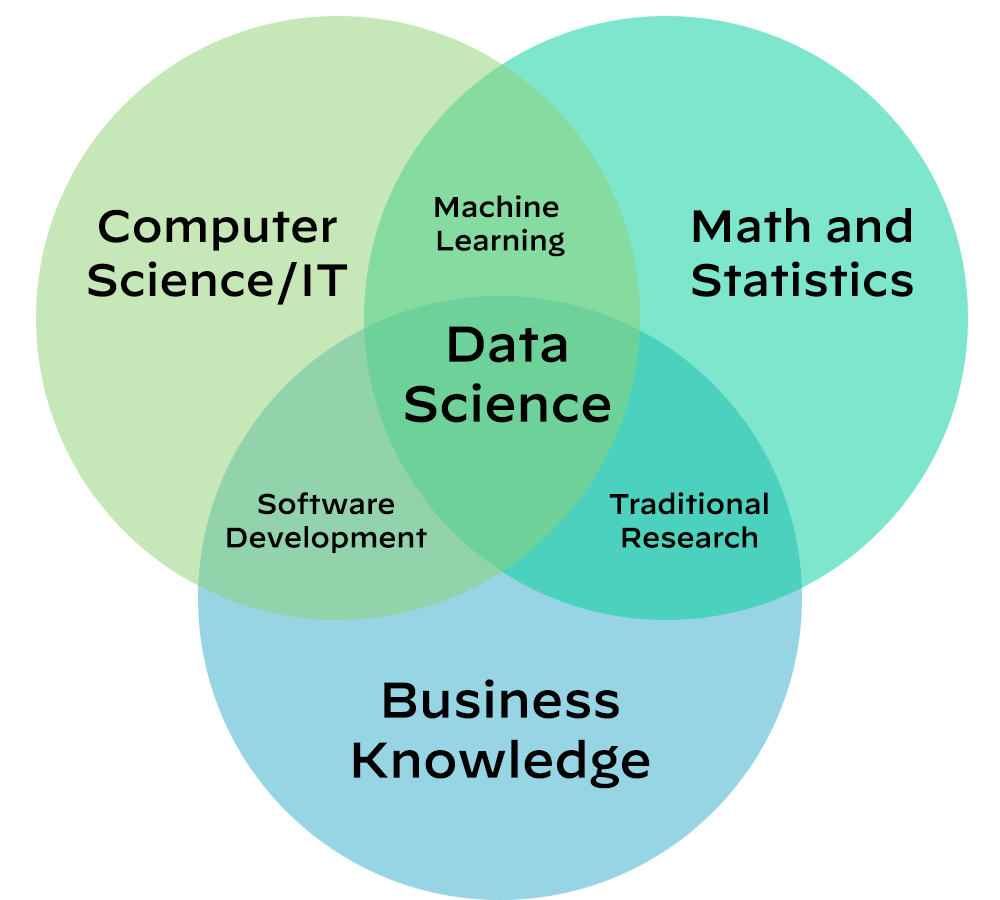
In recent years, there’s been a strong demand for full-stack data scientists, who are jack-of-all-trades engineers able to tackle every stage in the data science lifecycle. That includes identifying problems and deploying machine learning models to make an impact on the business.
I’ve encountered those early in their career who think that machine learning skills are enough, but that’s not the case. To be able to turn data into actionable insights, you really need the full stack of competencies. And if you happen to go into IT data science, there’s a series of cloud-based tech stacks that are essential, such as Spark, Jupyter notebook, Tableau, Airflow, Kubernetes, etc.
Data in Cybersecurity
I have worked in multiple industries such as finance, e-commerce, and cloud infrastructure. Before joining Palo Alto Networks, I spent three years in the networking industry because I believe networking — and cybersecurity — will be booming with AI and machine learning.
I believe this for two reasons. One, the volume of data generated is a precondition for applying machine learning. Two, most of the networking and cybersecurity operations cannot be done by humans. So it made sense for me to come to Palo Alto Networks where I can solve challenging problems using cutting-edge machine learning and data science techniques.
Customer Churn Prediction
One of the most interesting problems I’ve tackled at Palo Alto Networks is customer retention, which is important for any company with customers. Using ML techniques, we solved three major challenges, i.e., customer churn prediction, driving factor insight discovery, and high-churn customer retention guidance, to support the end-to-end operation of customer retention.
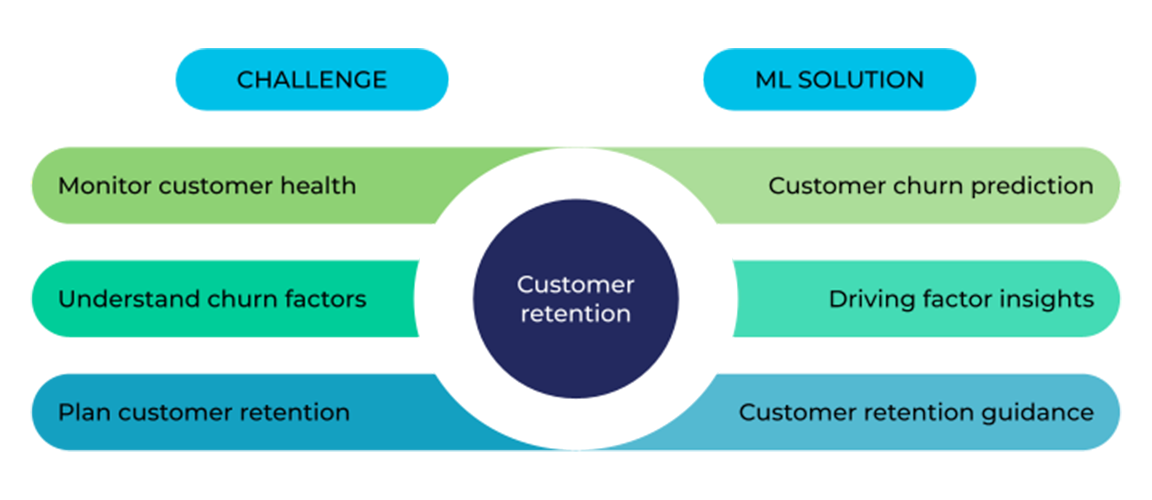
By taking advantage of the vast data source in the GCP data lake maintained by the IT data team, the churn prediction model automatically monitors the customer health regarding product adoption to capture the high-churn customers accurately and timely. The driving factor insight helps product managers identify the pain points of product adoption to improve customer experience. Perhaps what is most innovative — compared to existing work in the industry — is that we built an ML-driven retention guidance model to assess and recommend the best actions for customer engagement.
By assembling all the ML models in the generic google cloud infrastructure (GCP), a generalized customer churn analytics pipeline has been built and deployed for multiple product lines of Palo Alto Networks. It now supports different business stakeholders across the company, such as customer success management, go-to-market, corporate strategy, and product management.
To improve the performance of the ML models, more advanced techniques, such as feature engineering and selection, hyperparameter optimization, and causal inference modeling, were applied. We’ve also built a positive closed-loop feedback mechanism with business stakeholders so that we can get feedback on the prediction and recommendation results on time to enhance the models. Happy to say our models are helping our business retain costumes better.
Mindset Is Everything
I became a data scientist because I don’t like making decisions based on gut feelings as it invites back-and-forth arguing. The data is what it is, providing objectivity instead of guessing games. If you love objectivity, data science may be right for you.
Ultimately, as you build a successful career, be open to accepting new ideas or trying new approaches. Be curious. Curiosity is the motivation for self learning and advancement. Without it, you won’t be able to evolve your mindset and keep on growing.

If you enjoyed this post and would like to explore opportunities at Palo Alto Networks, check out our open roles. You can also read more stories like this or learn about our technologies.



